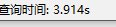##查数据 select t_client.mark,t_client.name,sum(countPeople) countPeople ,t_client.ip ip,t_count_people.countPeopleDetails from t_count_people,t_client where t_count_people.mark= t_client.mark and LENGTH(trim(t_count_people.mark))>1 and LENGTH(trim(t_client.name))>=1and t_client.id in (select cid from t_client_group_relation where uid=#uid#) and countDate <=#etime# and countDate >=#btime# groupby t_count_people.mark limit #startid#,#pagetype#
##统计数据总数 SELECT count(*) from ( select sum(countPeople) countPeople from t_count_people,t_client where t_count_people.mark= t_client.mark and LENGTH(trim(t_count_people.mark))>1 and LENGTH(trim(t_client.name))>=1and t_client.id in (select cid from t_client_group_relation where uid=#uid#) and countDate <=#etime# and countDate >=#btime# groupby t_count_people.mark ) temp
数据库表 t_count_people 人数统计表 10w条 数据
t_count_people通过t_result.id查出t_client的终端数据
t_result结果表 t_client 终端表
百度疯狂查资料。。 优化数据库查询合理使用索引,
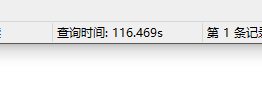
下面是我索引建立失误的查询时间
索引应当建立在频繁被作为查询条件的字段,这里说的是普通索引,唯一索引、主键索引我就不提了,
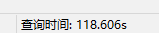
改正后发现也就提升了2秒左右的速度。。这还是毫无卵用啊。。。
我不得已对数据库 where进行拆分实验(直接select不带任何where 不超过3秒)
我终于发现了 大幅度影响速度的地方
and t_client.id in (select cid from t_client_group_relation where uid=#uid#)